





In this article I have covered : Introduction to Spark and its Architechture, RDDs and Spark DataFrames, translating b/w pandas and spark DataFrames, Writing SQL Queries and reading csv data into Spark Dataframes.
Getting to know py- Spark:
Spark is a platform for cluster computing. Spark lets you spread data and computations over clusters with multiple nodes (think of each node as a separate computer). Splitting up your data makes it easier to work with very large datasets because each node only works with a small amount of data.
PySpark is the Python API for Apache Spark. It enables you to perform real-time, large-scale data processing in a distributed environment using Python.

As each node works on its own subset of the total data, it also carries out a part of the total calculations required, so that both data processing and computation are performed in parallel over the nodes in the cluster. It is a fact that parallel computation can make certain types of programming tasks much faster.
However, with greater computing power comes greater complexity.
Deciding whether or not Spark is the best solution for your problem takes some experience, but you can consider questions like:
Is my data too big to work with on a single machine?
Can my calculations be easily parallelized?
https://spark.apache.org/docs/2.1.0/api/python/pyspark.html\
The first step in using Spark is connecting to a cluster.
In practice, the cluster will be hosted on a remote machine that's connected to all other nodes. There will be one computer, called the master that manages splitting up the data and the computations. The master is connected to the rest of the computers in the cluster, which are called worker. The master sends the workers data and calculations to run, and they send their results back to the master.
When you're just getting started with Spark it's simpler to just run a cluster locally. Thus, instead of connecting to another computer, all computations here will be run on a simulated cluster.
Creating the connection is as simple as creating an instance of the SparkContext class. The class constructor takes a few optional arguments that allow you to specify the attributes of the cluster you're connecting to.
An object holding all these attributes can be created with the SparkConf() constructor. Take a look at the documentation for all the details!
For the rest of this article you'll have a SparkContext called sc present.
Spark's core data structure is the Resilient Distributed Dataset (RDD). This is a low level object that lets Spark work its magic by splitting data across multiple nodes in the cluster. However, RDDs are hard to work with directly, so in this course you'll be using the Spark DataFrame abstraction built on top of RDDs.
The Spark DataFrame was designed to behave a lot like a SQL table (a table with variables in the columns and observations in the rows). Not only are they easier to understand, DataFrames are also more optimized for complicated operations than RDDs.
When you start modifying and combining columns and rows of data, there are many ways to arrive at the same result, but some often take much longer than others. When using RDDs, it's up to the data scientist to figure out the right way to optimize the query, but the DataFrame implementation has much of this optimization built in!
To start working with Spark DataFrames, you first have to create a SparkSession object from your SparkContext. You can think of the SparkContext as your connection to the cluster and the SparkSession as your interface with that connection.
Remember, for the rest of this article you'll have a SparkSession called spark present.
SparkSession has an attribute called catalog which lists all the data inside the cluster. This attribute has a few methods for extracting different pieces of information.
One of the most useful is the .listTables() method, which returns the names of all the tables in your cluster as a list.
We can run queries on the tables present in the cluster. use spark.sql() and pass it the query.
# Import SparkSession from pyspark.sql
from pyspark.sql import SparkSession
# Create spark
spark = SparkSession.builder.getOrCreate()
# Print the tables in the catalog
print(spark.catalog.listTables())
query = "FROM flights SELECT * LIMIT 10"
# Get the first 10 rows of flights
flights10 = spark.sql(query)
# Show the results
flights10.show()
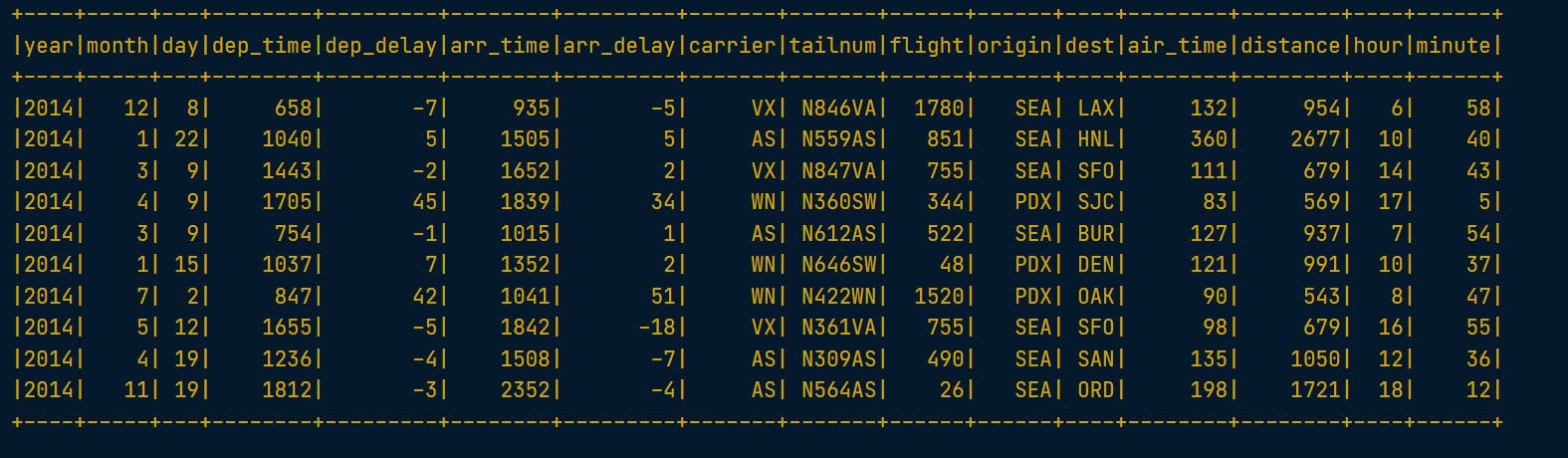
# Don't change this query
query = "SELECT origin, dest, COUNT(*) as N FROM flights GROUP BY origin, dest"
# Run the query
flight_counts = spark.sql(query)
# Sometimes it makes sense to then take that table and
# work with it locally using a tool like pandas.
# Spark DataFrames make that easy with the .toPandas() method.
# Calling this method on a Spark DataFrame returns the corresponding
# pandas DataFrame. It's as simple as that!#
# Convert the results to a pandas DataFrame
pd_counts = flight_counts.toPandas()
# Print the head of pd_counts
print(pd_counts.head())

Now earlier we queries the data and converted it to dataframe, now we can do it the other way around too.
The .createDataFrame() method takes a pandas DataFrame and returns a Spark DataFrame, and put a pandas DataFrame into a Spark cluster!
The output of this method is stored locally, not in the SparkSession catalog. This means that you can use all the Spark DataFrame methods on it, but you can't access the data in other contexts.
For example, a SQL query (using the .sql() method) that references your DataFrame will throw an error. To access the data in this way, you have to save it as a temporary table.
You can do this using the .createTempView() Spark DataFrame method, which takes as its only argument the name of the temporary table you'd like to register. This method registers the DataFrame as a table in the catalog, but as this table is temporary, it can only be accessed from the specific SparkSession used to create the Spark DataFrame.
There is also the method .createOrReplaceTempView(). This safely creates a new temporary table if nothing was there before, or updates an existing table if one was already defined. You'll use this method to avoid running into problems with duplicate tables.
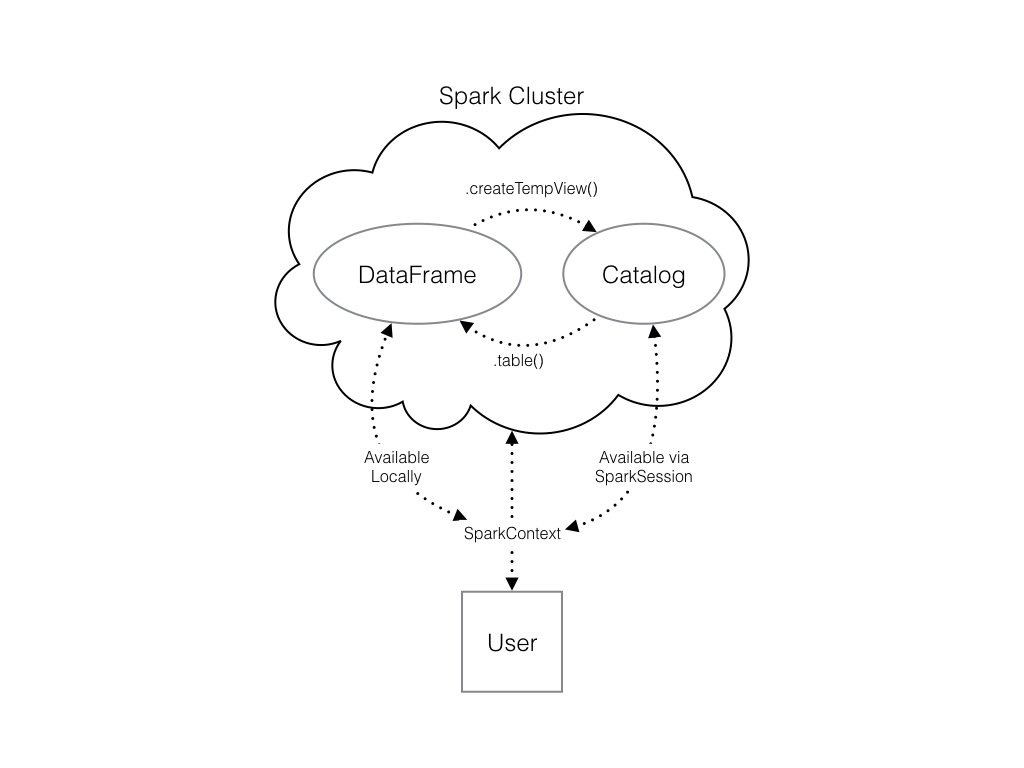
Check out the diagram to see all the different ways your Spark data structures interact with each other.
# Create pd_temp dataframe
pd_temp = pd.DataFrame(np.random.random(10))
# Create spark_temp from pd_temp
spark_temp = spark.createDataFrame(pd_temp)
# Examine the tables in the catalog
print(spark.catalog.listTables())
# Add spark_temp to the catalog
spark_temp.createOrReplaceTempView("temp")
# Examine the tables in the catalog again
print(spark.catalog.listTables())
Now you know how to put data into Spark via pandas, but you're probably wondering why deal with pandas at all? Wouldn't it be easier to just read a text file straight into Spark? Of course it would!
Luckily, your SparkSession has a .read attribute which has several methods for reading different data sources into Spark DataFrames. Using these you can create a DataFrame from a .csv file just like with regular pandas DataFrames!
The variable file_path is a string with the path to the file airports.csv. This file contains information about different airports all over the world.
# Don't change this file path
file_path = "/usr/local/share/datasets/airports.csv"
# Read in the airports data
airports = spark.read.csv(file_path, header=True)
# Pass the argument header=True so that Spark
# knows to take the column names from the first line of the file.
# Show the data
airports.show()

This was the First of Many Articles on pySpark. Stay tuned for more.